
How to train a good model 1
How to train a good model
A good setup
To train a good model, apart from designing an overall model structure, we should prepare suitable training components for our training to get the model converge. They includes:
Activation functions
Use ReLU for the first hand, may be good enough
data preprocessing
Depending on the tasks, different Conv Nets structure use different data preprocessing techniques.

weight initialization (Kaiming & Xavier initialization)
We can initialize the weight according to gaussian distribution with mean 0 and arbitrary standard deviation. But it turns out that bigger or smaller
stdwill all hamper the convergence of the model.Kaiming and Xavier initialization deals with the initialization problem. Specifically, Kaiming method is an extension of Xavier’s with respect to ReLU activation circumstances.
The formular of Kaiming & Xavier initialization should be:
$$
\sigma = \sqrt{\frac{k}{D_{in}}} \space
$$
In the above formular,$\sigma$ is the standard deviation over this batch of data
k = 2 if the layer in which lays our weight matrix to be initialized contains a ReLU function, which is the Kaiming method. And k=1 if not ReLU, is the Xavier method.
$D_{in}$ is the number of the inputs that is sent to a single neuron / kernel and spit out a single output. For example, for FC layer, $D_{in}$ is the dimension of a single sample, for convolution layer, $D{in}$ is
feature_number * kernel_size * kernal_size. The common points is that they are all sent to a column of W or a kernel and output a single scalar in the output matrix.
The derivation of the method is about keeping the variance of output = variance of input in a layer. Detained steps please refer to cs231 notes.
regularization( broadly include Dropouts and Batch Normalizations)
L2 and L1-norm regularization are common in shallow network architecture.
Other methods including Elastic net regularization and Max-norm regularization` are available but not used often.
Dropout is another very useful and once popular method of regularization. Dropout claims to improve robustness by randomly dropout some neurons, which prevents overfitting by inhibiting feature co-expression on nodes (overmixing distinctive and informative features).
Others see dropout as a result of ensembled learning on subnetworks from the whole network. However global pooling layers have take the place of dropout in large neural networks in recent works.Batch Normalization is another widely used method in Deep network model. One way of interpreting BN is its regularization property. Because BN normalize the data for each feature, across all the samples in a batch. This is similar to what L1 & L2 norm do to the loss function & data in a batch. But also Batch Normalization can be interpreted as a way of online/in-model data ‘pre’ processing. It did similar job to data preprocessing, but is integrated in the model training and requires updates on its only parameters using front/backpropagation. The details of batch normalization can be see in this class video
To clarify, these are not the hyperparameters in model training, but more sort of options that may change the whole model structure.
Choosing the right spare parts is the first step of training a good model. But online tuning is also crucial for a network model to converge.
Training techniques
There are several process that we need to follow to train a good model by hand.
Sanity checks
Sanity checks deals with the implementation errors in the model design. We can check loss and gradient by running one round of model.loss(X_train, y_train=None) .
- Loss checking
By a single computation, the loss function value should be closely relative to the loss function and weight initialization, not the data distribution. For example, insoftmaxwe expect loss = $\log C$ for $C$ class supervised classification learning. - Gradient checking
We can use numeric gradient checking to assure the correctness in backprop. We should use artificial data in small scale and running one round ofmodel.loss(X_train,y_train). We expect a close value between the numerical result and the analytical results. - Overfit a small data set
Tune the parameter on a small training set that achieve 100% accuracy (likely getting low validation accuracy). For example, take 100 samples, use 30 epochs, within each epoch, use SGD to fetch a batch_size of 50 samples (accounts for 100//50 = 2 iterations per epoch).
For details please refer to the class notes
Watching the Dashboards
Accuracy on training and validation
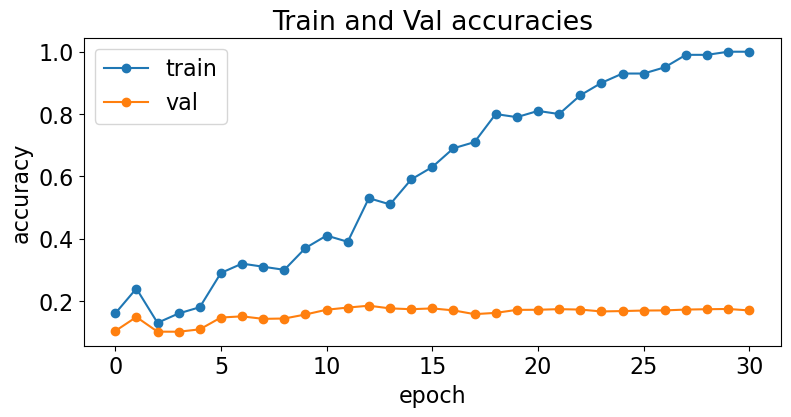
Loss value
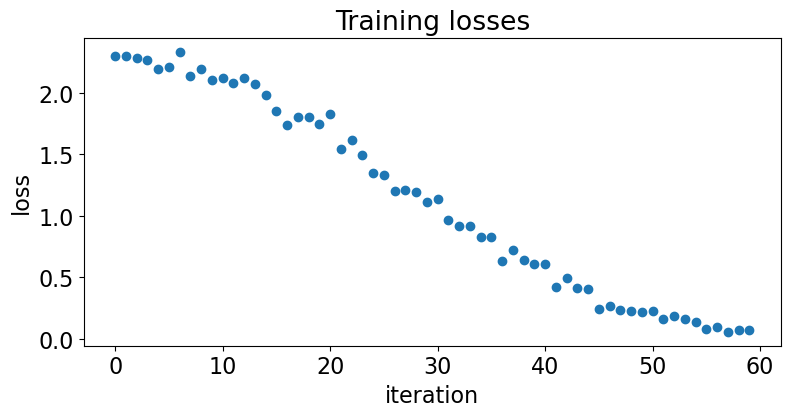
These are the two important indicators of training, make sure to look at the two picture in tuning.
Update rules
Several GD rules have been developed these years. In default we can use the Adam method.
Hyperparameters tuning
There are two common source of hyperparams in network training.
The first is from the configuration params of model components, like hidden_layers, num_filters , regularization_strength and so on. They are related more closely to the performance of the model.
The second is from the solver’s params, like learning_rates , update_rules and so on. They are related more closely to the convergence of the model.
Among them, Learning rates and its decays are utmost important for most training tasks.
Before we use random search, we should first pinpoint a suitable range for our search. We can use method of Overfitting small data
Then, try to optimize the learning rate, lr_decay and regularization strength first.
Finally, tune other parameters to the best effort.
Several notice:
Use one large validation set is enough
Use random search
Further, if the best value is on the edge of the range, try again with modified range
From coarse to fine
At first, do broad range search with relatively small number of epochs. After that, narrow down to a more optimized range and increase epochs.
For example, a training code may look like this:
1 | #... |
Afterward training
TBD







