
A Brief to LangChain
LangChain
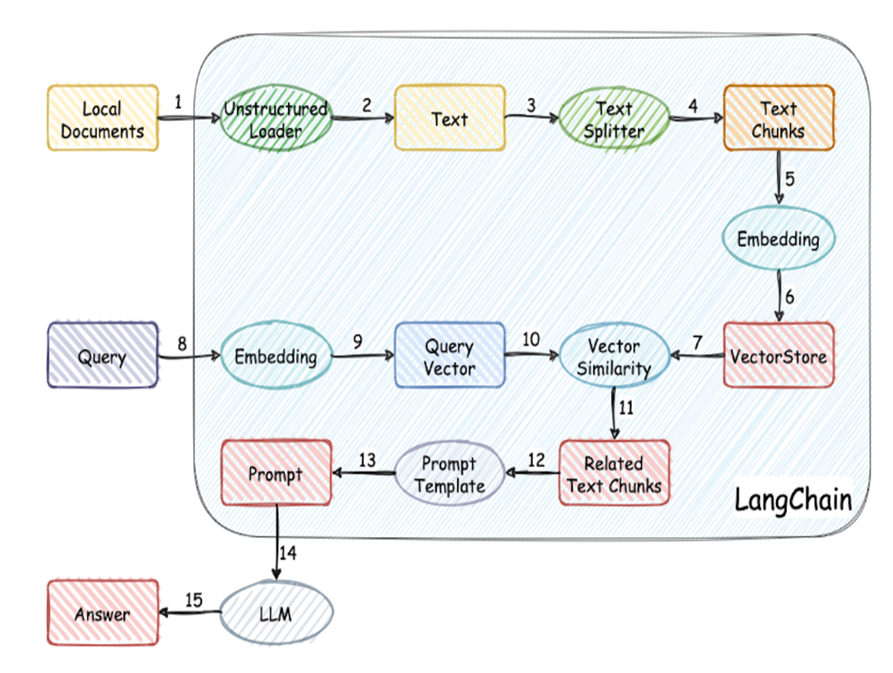
LangChain is a platform and a framework for developers to build LLM based applications. The illustration above shows what LangChain as a platform does in an LLM based QA application, and its basic constitution.
The ellipsoid block in the illustration are functions provided in LangChain package, and the square blocks are the type of information or the generated results in the process. (Not all the functions / modules are provided solely by LangChain, but by open source frameworks, like Vector-Store modules, but LangChain has smoothly integrated them in its pipeline.
The Design of LangChain, its information flow all center around the foremost part in LLM-based applications, the models. LangChain enables developers to build workflow or pipelines particular for the models we choose, involving pre-processing data, vector storage, memory and its retrieval, model I/O (prompt generation and calling the LLM models), and so on.
Here is another image that demonstrate how LangChain supports a GPT-4 based Chat application.
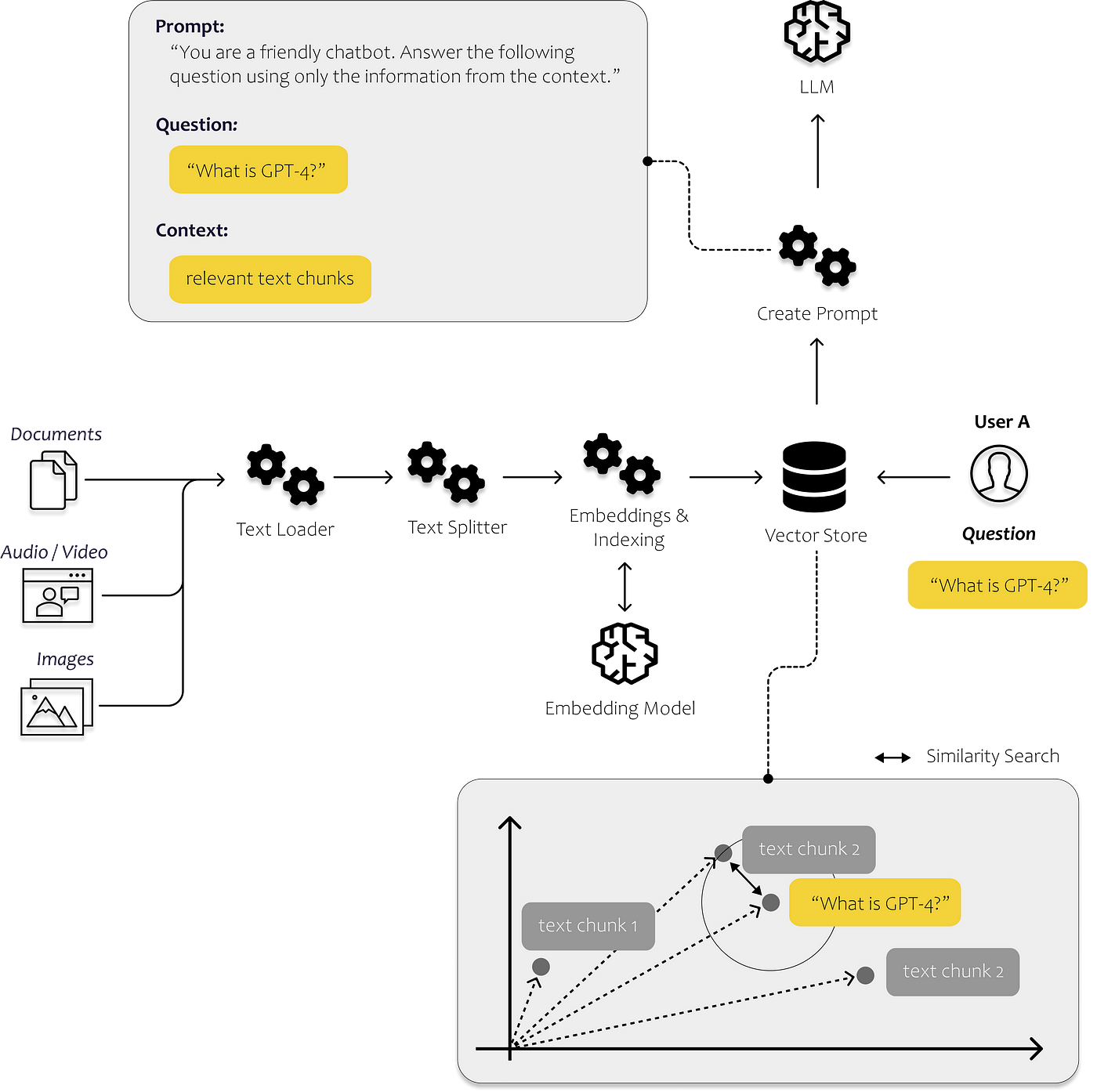
To understand the image, we should follow the flow of information.
In the pre-training process, Documents are loaded and transformed using a chain of data processing tool provided by LangChain, including text-loader , text-splitter , embedding .
After pre-processing, the documents have turned into vectors, (maybe one sentence / one semantic block for one vector). We then utilized a vectorStore to store these vectors for further retrieval.
Then a user can start to raise question. The user input is first pre-processed using the same procedure to get a query vector. The vector is first used to compare similarity with the vectors in the vector store. Similar vectors are retrieved from the storage as relevant context which will be provided to the prompt generator together with the original query vector. Some other information which is not mentioned in the illustration can also be passed, such as chat context, and policies.
The data are not sent to the LLM models directly, instead we use an components group Model I/O to handle jobs comprising prompt creating and output parsing that may be distinctive between the models. Developers can also use prompt templates to quickly generate required prompts from the input data, memory and contexts. Then the prompt will be given to the LLM model and (if online model) pending for response. This is usually done by letting LangChain call API from LLM providers. Finally If LangChain framework detects the response, we can also preform information extraction before the user sees the response, and expose the most relevant K answers or return the transformed answers back to the users. We can also dictate what will be stored in the memory, so that it can be invoked in the following QA session.







