
BERT Paper Notes
Preface
In short, BERT uses the Transformer and a bi-directional training method, use unlabeled text to pre-train a model that generate useful representations of the input text tokens. These representations can be used to drive various tasks after only fine-tuning the additional output layer for different purposes.
In model design, BERT inherit most transformer properties, but discard the separated decoder. Therefore the input method should be modified as well.
In pre-training technique, two main approach comprises the meaning of “Bidirectional”. The masked language model and the “next sentence prediction” both contributes to the pre-train of “text-pair representations”.
Some tips are written in the quotes. We mainly revolve around the above topics to begin the introduction of BERT.
Token-based and Sentence-based Tasks
In brief, they differ in the granularity of the input and output, token-based tasks being finer. For example, the embedded vector in token-based model usually prepare a vector for each token, while sentence-based tasks usually prepare view a sentence as a unit. BERT is a token-based model.
GPT link: https://chat.openai.com/share/94931112-43c1-4ac8-96f4-0b70db30d187
Feature-based and Fine-tuning
Feature-based approach changes model architecture for different tasks and collect corresponding feature for each task (like embedded word vectors). Fine-tuning method allows a pre-trained model to be applied almost directly to different tasks only requiring tuning some hyperparameters based on downstream data.
It is crucial that BERT is pre-trained and itself after pre-training is only responsible for providing the embedded representation of original text tokens. BERT does not know the downstream tasks during pre-training, and neither do we need to modify BERT itself in downstream tasks.
Introduction and Preliminaries
Transformer Review
BERT use the exactly same architecture as the Transformer. The following illustration is a Review of the model.
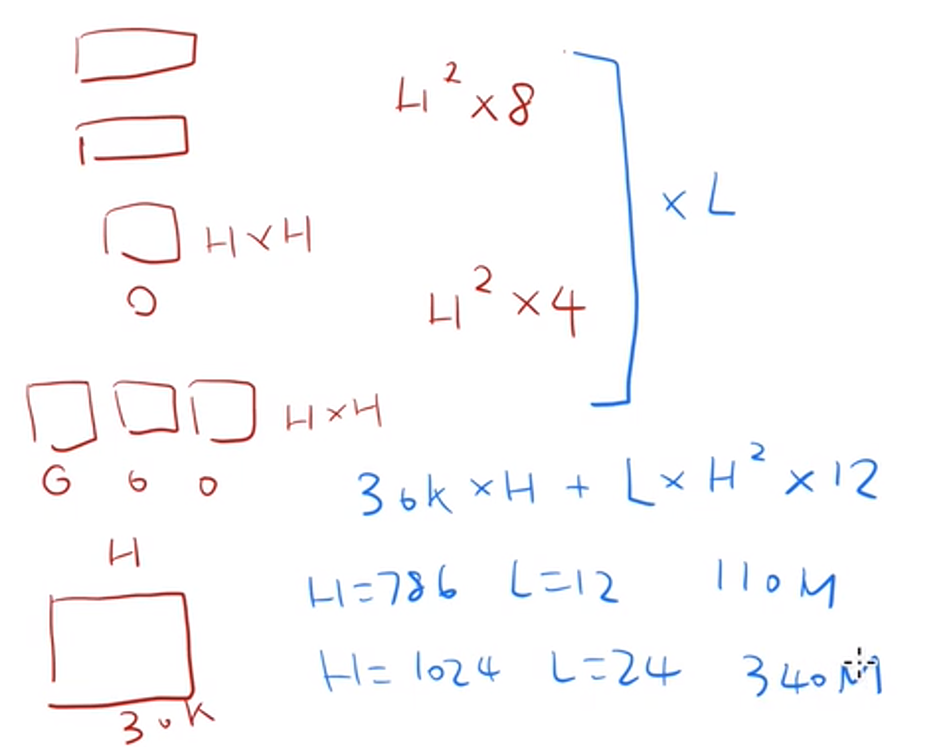
Here is the detailed text version explanation.
Moreover, BERT see the positional encoding as a sort of learnable parameters, not a manually tweaked parameter.
BERT Architecture
Transformer in BERT
Bert itself does not handle particular tasks, but is a pre-trained model that generate representation for input tokens. It purely stack multiple Transformer layers together and collect the last layer output as the learnable representation by BERT for each input. Then for various different tasks, we need to modify the top layer which utilize the context generated by BERT and serve particular output.
No splitted Encoder and Decoder in BERT
In original Transformer architecture, the encoder and the decoder use separated learnable parameters, and we pair the input with the desired output and feed correspondingly into the encoder and the decoder during training. For example, in machine translation, the embedded layer in decoder can be different from the encoder. The weight matrix in decoder may represent for French, and that of the encoder may represent for English. This separated structure enables the Transformer to do machine translation tasks, image labelling tasks, but may also sacrifice accuracy in some extent, due to the independence between the encoder and the decoder.
Bert uses a combined structure, getting rid of the encoder and the decoder separation, but in turn the input and output should be intrinsically homogeneous.
Input Design in BERT
Inputting two sentence at a time requires additional design of BERT.
The overall design is as follow:
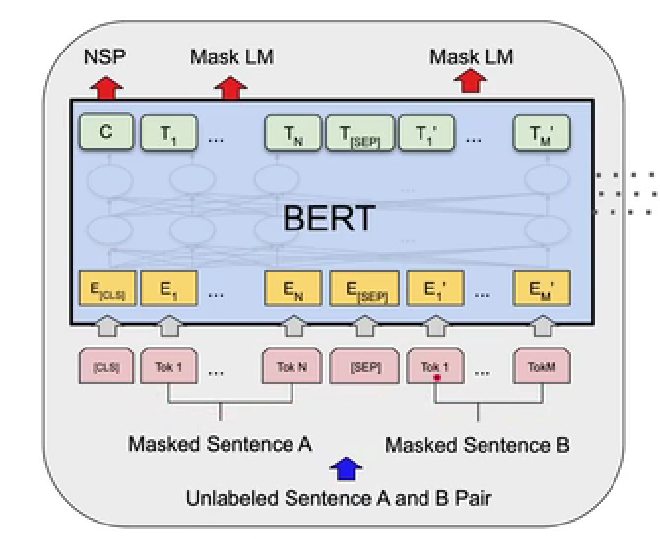
Before dealing with the different input method, we first introduce how BERT tokenize words. BERT tokenize word in very fine granularity. Even word can be tokenized into parts like suffix and prefix, which managed to scale down the length of word dictionary. For example, countless can be tokenized into count and less.
Owning to the integral design of the model, BERT is naturally suit for single sequence input, the way BERT deals with different two sentences in a pair need to be introduced.
To design a way of inputting a sentence pair (to cater for more downstream tasks), the method BERT takes is to insert <CLS> at the start of the first sentence and <SEP> in between. The group is then sent to BERT in the same way as others.
Then, given the requirement of recognize the sentence before <SEP> or after that, the way the word is embedded needs to be modified
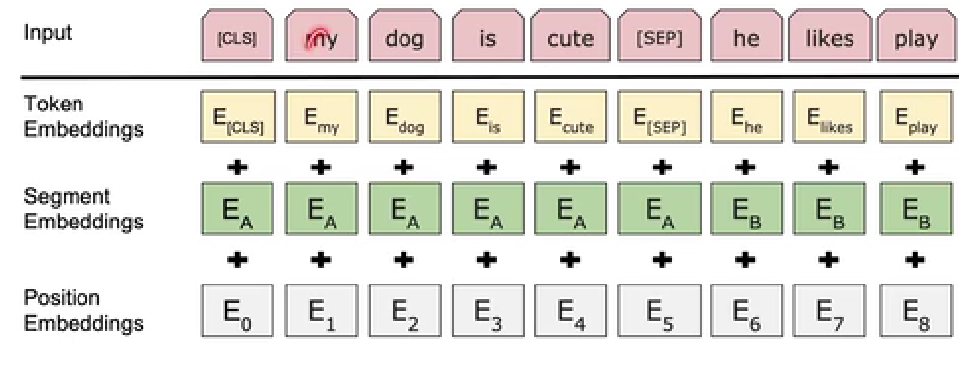
Bidirectional in BERT Pre-training
We proceed to see how BERT is trained bi-directionally.
Masked token prediction
15% of the words in a sentence are randomly selected for prediction. But the words selected for prediction are not necessarily replaced with the MASK token (because the downstream task does not have this token, introducing some inconsistency): 80% are replaced with the MASK token; 10% are replaced with a random token; 10% are not replaced.
The procedure of pre-training goes as said in the link below:
GPT conversation link: https://chat.openai.com/share/8a4ce098-9816-4802-bc55-e8d9de2012af
An interesting concept for self-attention is that the way self-attention receives only one input facilitate us to use self-attention to receive what ever input we want to find similarity in the context. The input can be hidden state in Transformer decoders, feature vectors in Transformer encoders in CV, and literally text tokens in NLP missions.
The 10% choice of non-replacement takes into consideration the need for maintaining similarity with the fine-tuning process because we don’t use mask-prediction in downstream tasks. The 10% choice of random substitution account for introducing turbulence. The 80% choice of replacement is where the pre-training really take place.
Next Sentence Prediction
This is one place we actually need the way of inputting two sentence in a pair. We sent the sentence (A, B) as 50% being correctly ordered as in their original paragraph, and 50% being not in order. The prediction is to let BERT determine whether the they are aligned correctly or not.








