
GPT-1 -2 -3 Paper Note
GPT-1 -2 -3 -4 Paper Note
[toc]
GPT-1
先于BERT首个提出预训练和微调架构的模型方案,相比BERT使用的数据集和模型参数大小都略少。GPT-1的预训练加微调的两步走的训练方案以及其细节,解决了NLP领域一直举棋不定的一些问题,比如损失函数的确定,不同任务的输入输出,训练方案等等。
预训练
在预训练方面解决了训练任务的确定问题,具体为确定了损失函数(训练任务),使用非标号文本,使用带掩码的Transformer解码器。如下所示的是预训练的损失函数,可以认为是给定模型$\Theta$,给定前k个token构成的窗口用来预测第k+1个单词。构成的损失函数则是生成式模型中类似autoregressive的损失函数
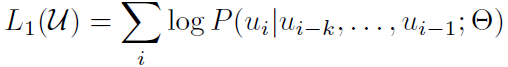
微调
在微调方面,GPT-1的贡献在于为多个不同的NLP任务确定了不同的微调架构, 具体地说,对不同任务也会有稍微不同的损失函数,不同的任务数据输入方式也会进行调整(task-specific input method),同时这部分将是监督学习。
以下是微调任务中的损失函数:
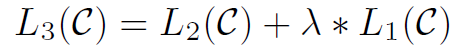
在以上的损失函数中,L2是针对特定任务的监督式学习的损失函数,L1是预训练任务的损失函数,意思是两种训练任务将同时进行完成微调环节,最终的损失函数将使用超参数$\lambda$ 线性连接起来。
微调任务为不同NLP任务设计的输入输出方式如下所示: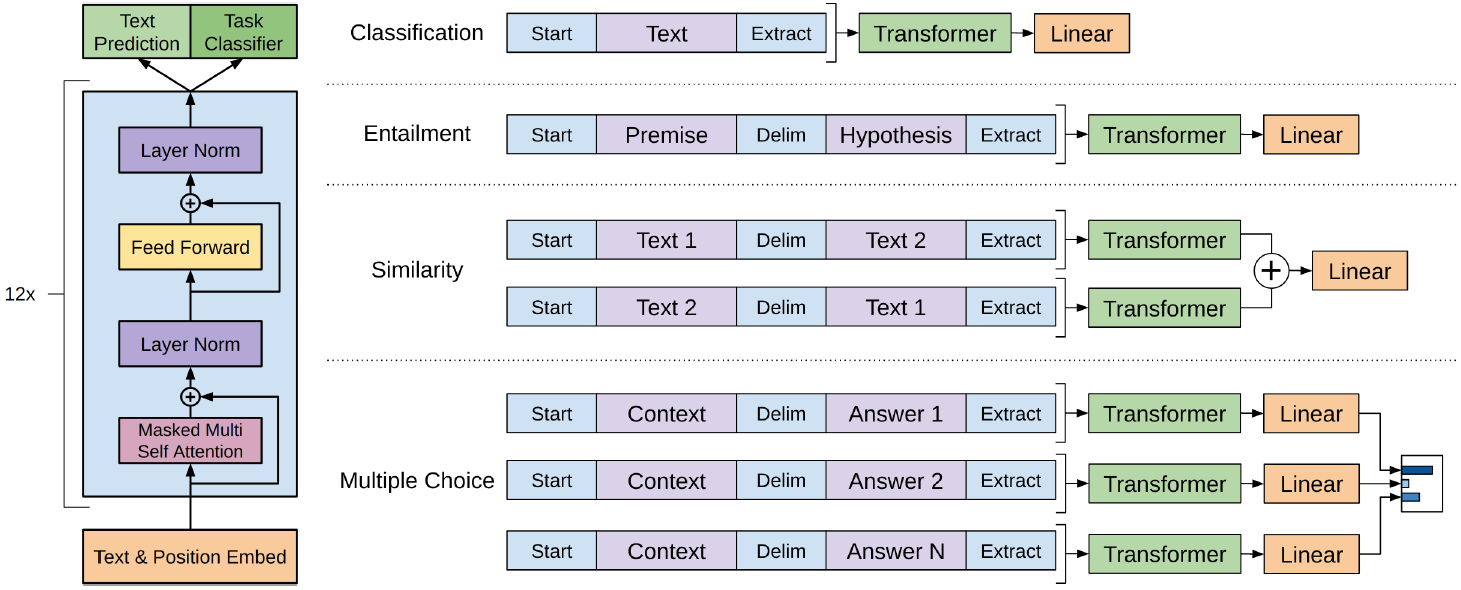
各任务介绍:
分类任务(Classification)就是最常见的多分类任务,比如一段话在描述什么东西。Entailment 是给出一段话和一句假设,判断前一句话是否支持后一句的假设,本质是T/F/DK的三分类问题。
Similarity 是给出两句话,判断二者是否显示。由于相似是对称性的,所以两个句子要额外地颠倒顺序后重新作为数据。这两个顺序的结果最后做加权评分,判断分类结果。
多选题问题 (Multiple Choice),就是简单的多分类问题。
GPT-2
GPT-2 的创新之处在于引入了zero-shot的概念。同时,增加了数据集的数量,使得性能相较一代和竞品BERT相比有了一定的提升。
Zero-shot & prompt
zero-shot意思是将预训练模型不经过fine-tuning直接用于下游任务。首先需要克服的问题是预训练任务和下游任务中的输入输出需要相对同质,比如说在训练中就不能再引入句子开始和结束的特殊标识符,因为zero-shot中下游任务不会特别为你准备好一样类型处理好的输入输出。我们使用的代替方法是使用prompt。
prompt方法是使用自然语言去描述下游任务的目标,并将这段话放在任务输入的最前面,一起输入预训练的模型。比如说,翻译英文”Hello world”到中文“你好世界“的任务,可以使用的的输入如”translate to Chinese: Hello world =>” 然后预期的翻译任务输出就是”你好世界“。
论文作者认为zero-shot 可能成功的原因在于其一可能是模型真的理解了prompt的含义,其二可能是模型用于训练的数据中本身就有很多自然的prompt+action的数据,比如试卷就容易出现翻译题,而模型可能不知道prompt什么意思,只是因为数据中有较多类似的结构,就照葫芦画瓢了。反正怎么解释都对嘛。
在论文中,作者额外介绍了使用的数据集构建方法,GPT-2使用的reddit上超过三人赞同(karma)的帖子作为数据,相比CommonScraper数据集来说,相对质量较高。
最终的结果zero-shot不算太差,所以论文就发出来了。
GPT-3
相比GPT-2 中激进地使用zero-shot,GPT-3通过增加大量样本量,取few-shot做下游任务迁移的方式,获得了较大的性能提升。
Few-shot & In-context Learning
GPT-3中很重要的新概念是few-shot,以及其所属的in-context learning。In-context learning 的产生背景在于GPT-3等大模型的参数数量惊人地多。即使使用相对较少的样本对下游任务进行fine-tuning也显得开销十分惊人。GPT-3提出使用in-context learning中的few-shot解决这个问题,in-context learning的定义就是不进行fine-tuning,不对大模型的参数进行训练更新,而是在输入的上下文中加入相关内容,使得模型理解下游任务,或说通过理解了输入中的信息进行微调。具体到few-shot,其原理为,基于在zero-shot中做出的假设,我们认为模型已经能够通过prompt接收并理解下游的具体任务,不同于zero-shot直接给出prompt描述问题本身后结束,few-shot在prompt和具体输入之间,还给出了一些范例。比如之前的语言翻译的例子,few-shot的输入应为比如:
1 | "translate to Chinese, |
通过few-shot这种带例子的输入,我们希望模型通过注意力机制,在输入的上下文中找到合适的信息,用于精调自己的回答,达到微调的效果。相比fine-tuning,in-context learning没有更新模型的计算量,代价是微调数据量较小,准确度则没有完全fine-tuning可能达到的效果好,但是效果也十分不错了。
在模型架构中除了transformer替换为了Sparse Transformer,其他的和GPT-2完全一致。
GPT-4
GPT-4 主要的工作在于Predictable Scaling + RLHF + 多模态,同时在数据集的选择上也有自己的思考。
Predictable Scaling
Predictable Scaling 方法,是通过在比GPT-4模型小10000x的模型上训练,得到的loss用来预测相同条件下在GPT-4大模型下得到的loss。在GPT-4的技术报告中,openai绘制了不同大小的模型的结果和实际GPT结果的拟合曲线,显示随着模型的大小逐渐增加,loss的分布基本遵循 power law 函数。

RLHF
RLHF方法,全称是 Reinforced Learning with Human Feedback,是一种微调方法。该方法首先在描述ChatGPT的论文 InstructGPT 中被记录。RLHF的目的是使得模型与人类的意图对齐 (alignment) ,使其明白应该何时回答问题,怎么回答问题,符合人类的思维方式。下面介绍 RLHF的方法
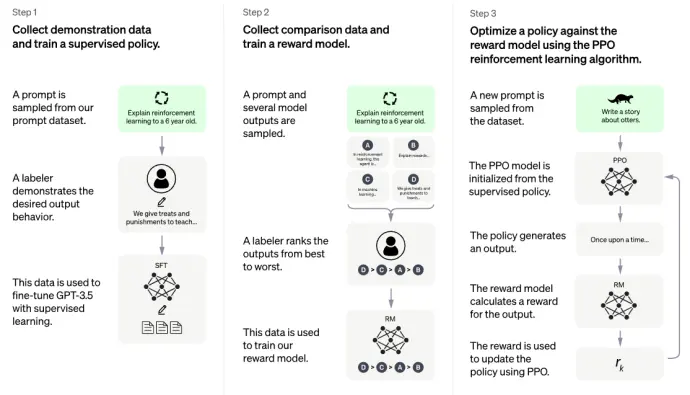
首先我们需要理解RLHF产生的原因。由于语言模型是利用未标号的数据的自监督模型,所以模型的能力几乎完全取决于数据集的好坏。然而,生成对话式的文本需要考虑与人类意图对齐和安全性等因素,因此无论怎样表述,仍然需要收集一定的数据集例子进行最后的”微调“才能达到最好的效果。
RHLF的做法是使用人类的反馈进行微调,而非使用带标签的数据进行微调。概括来说就是首先标注一些prompt和回答的数据集,然后微调一个模型。然后再训练一些prompt和多个排序回答的数据集,然后用强化学习再训练出一个模型。具体的分析如下:
训练SFT
第一步,如上图的左1/3所述,是收集来自用户使用GPT过程中提出的prompt,然后雇人专门为这些prompt写正确的答案,由此形成一个数据集。在这个数据集上对GPT-3进行微调,得到的新模型称为SFT。
训练RM
第二步,如上图中间所示,还是先收集一定的prompt数据,然后对每个prompt收集k个可能的回答(不一定是人写的),构成新的数据集。接着,对每个prompt,人对它的那些k个回答进行排序(对应 human Feedback),并训练一个强化学习的奖励模型(RM),目标同样是给这k个回答排序得和人的选则越接近越好。一旦这个RM模型训练好了,就可以用来自动给任意的k个答案打分了。
值得注意的是训练RM时使用的损失函数 Pairwise Ranking Loss
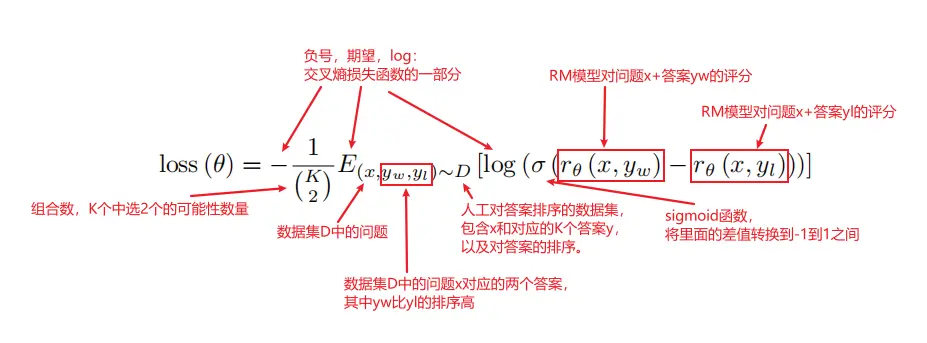
这个损失函数的左右就是衡量比如说abcd排成adcb,误差有多大。
对损失函数提供如下解释:

一些疑难解答

训练RL Policy(得到InstructGPT)
第三步,使用RL中的PPO算法,用RM模型去不断微调第一步中的SFT。用强化学习的语境说,通过RL训练中的模型是一个Policy,初始时被assign为SFT。由于每次的对Policy的更新,环境中的数据分布在不断变化,这是强化学习相较于普通的概率分布模型的一个显著的区别。(x代表的prompt虽然抽样于相同的数据集中,但是y代表的回答时RL训练中的模型所生成的,其分布是不断在变化的)。每次我们有一个Prompt并调用SFT生成k个回答,我们就用RM给这k个回答打分,然后通过(朝 max 方向)优化下面的魔改PPO损失函数(论文中称为PPO-ptx)使得生成的答案更接近于打分高的模型。

我们来结合具体的任务来分析上述损失函数。
首先查看第一个期望
$$
\begin{aligned}
E_{(x, y) \sim D_{\pi_\phi^{\mathrm{RL}}}}\left[r_\theta(x, y)-\beta \log \left(\pi_\phi^{\mathrm{RL}}(y \mid x) / \pi^{\mathrm{SFT}}(y \mid x)\right)\right]
\end{aligned}
$$
- 该期望的概率空间是基于RL模型生成回答时的问答对,分布记为$D_{\pi_\phi^{\mathrm{RL}}}$.
- $r_{\theta} (x,y)$ 是RM模型对该问答对的奖励分数(理解为排序后打的评分也行),期望是越高越好。
- $\beta \log(\cdot)$ 结合期望的概率空间是$D_{\pi_\phi^{\mathrm{RL}}}$ 来看,是RL模型的问答对概率分布和原SFT模型问答对概率分布的KL散度,要求散度越低越好,意为RL模型不应偏离原来的的模型过多,力度由超参数$\beta$ 控制。
再来查看第二个期望
$$
\gamma E_{x \sim D_{\text {pretrain }}}\left[\log \left(\pi_\phi^{\mathrm{RL}}(x)\right)\right]
$$
这其实是类似训练GPT-3的目标函数的, ,概率空间是原先GPT-3的训练数据集,$\pi_\phi^{\mathrm{RL}}(x)$ 表示本轮RL生成的模型,生成GPT-3训练数据集中的 token x 的概率 ,因此总体套上最大似然,旨在优化RL的参数使得生成出原数据集数据的概率越大越好。这样设计目标函数的意义是使得训练出来的模型不至于退化到高度拟合于具体的任务。但是并没有说明计算一个token x的概率分布公式?,难道是抽样估计?还是是类似autoencoder的计算公式。
一些博客中给出的解释是训练GPT-3的原本的目标函数,但是GPT-3(基本同GPT-2)原本的目标函数也不甚清楚,只能做出一些假设了。
如何使生成式语言模型输出每个对应输入的每个token的概率
当然,softmax 输出的就是概率

最后的得到的损失函数用来更新Policy,也就是RL模型。至此主要概括了RLHF方法的主要内容。
总结
综上,以上是对GPT-1-2-3系列的一些个人总结。做如上记录。







