
Paper Review: Towards Federated Learning At Scale - a System Design
This paper is the famous paper from Google that introduce how to build a system for FL. Google has used it to build Gboard and several other apps.
The paper first introduce the system from the time perspective. Then it describe it in device perspective and server perspective. After that the paper details in how we analysis and monitor the system. Following that is the intro of practical tools /add-on that can be used by engineers or can be installed to improve the system. Finally, the paper mentions some open questions and related work to which it calls for more attentions.
Timeline analysis of the model
From the time perspective, the model is divided by three phase that is executed in order and repeatedly.
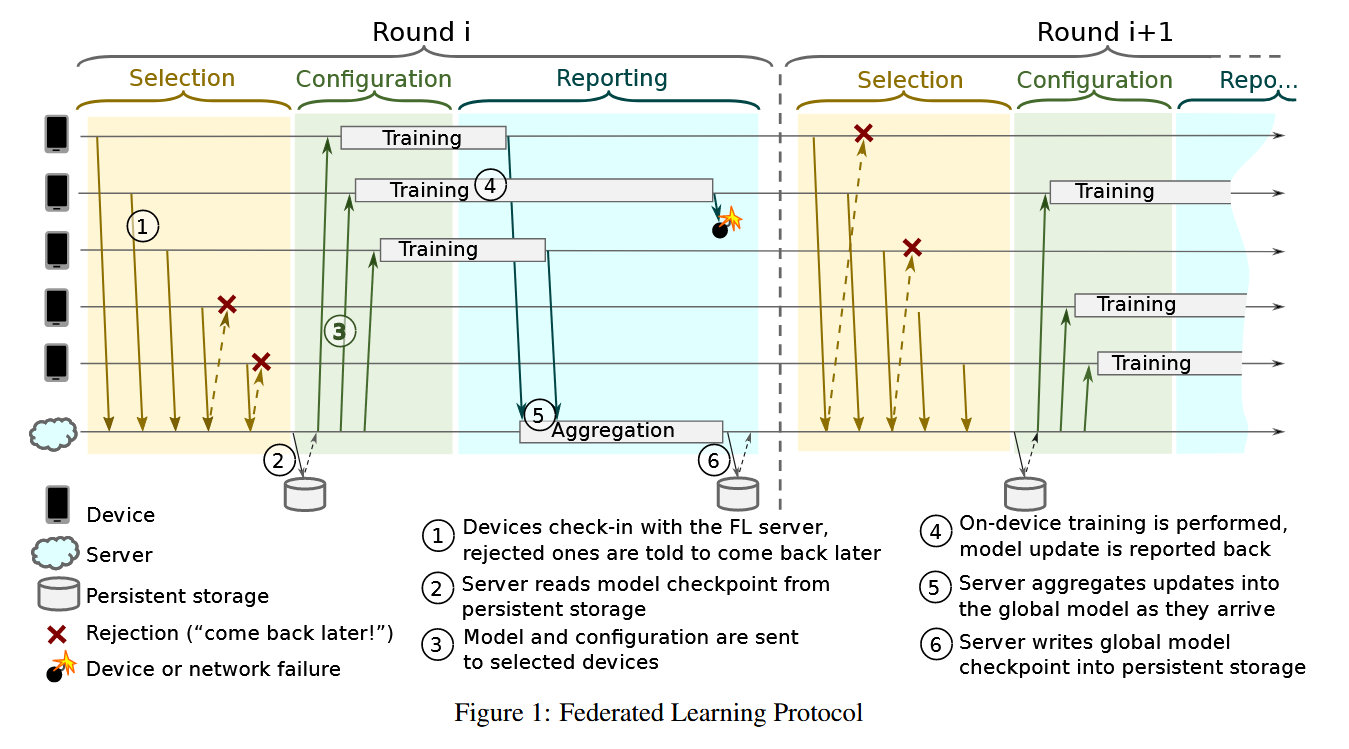
Selection:
The device check-in and the cloud server chose a subset from the check-in models. They will be then arranged in the following phases to perform an FL task in an FL population (think of FL population as an app, and the FL task is a task in a big mission or an app). Those rejected will be told to come back later.
The server then loads the progress (check points) from the memory for continuing previous training process.
Configuration
Then models and instructions for the distributed FL tasks are sent to the device in that subset. The training is started in the devices.
Reporting
If succeed, the device report back and upload the result (either the evaluation of model on its local data or a trained submodel/model parameters). If failed they report nothing and the server in default drop out the unreported devices.
There are some specifications on the implementation of the phases.
First, the server informs the selected devices what computation to run with an FL plan, a data structure that includes a TensorFlow graph and instructions for how to execute it.
Second, the device not only just performs the computation works for the server, it also receives updated global model and update its own program. Original FL does not a personalized local model within each device. Only data is locally different, the model is the same within one round, among different devices.
Third, they introduced a technique called Pace Steering, a flow control mechanism regulating the pattern of device connection. Simply speaking, Pace Steering is a method that cloud server plans and tells the devices when they should come back again, thus managed to control the speed of FL progress and the flow condition. More specifically, under small FL populations Pace Steering ensures the sufficient amount of devices simultaneously available, which is essential for task progress rate and efficiency of the security aggregation protocol. While under large FL populations, Pace Steering advocates the devices to adopt randomize check-in times and maintain necessary but not excessive re-querying rate to both support a big quantity of FL tasks and mitigate flow congestions.
Device-side Design
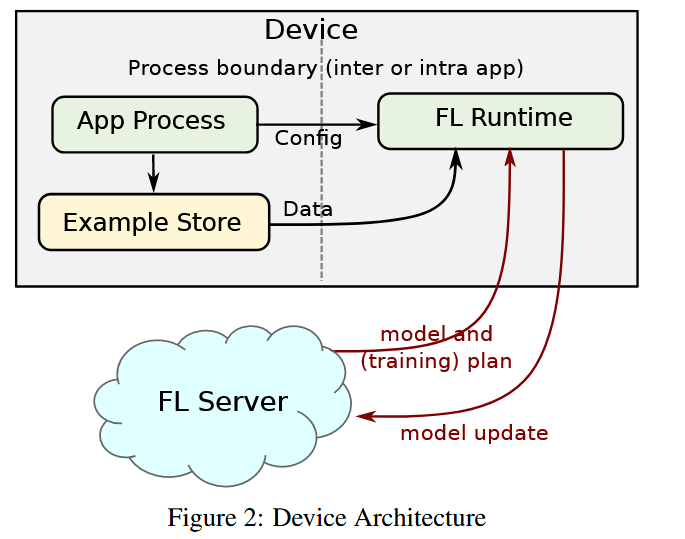
The device-side architecture generally consists of three important concepts: the APP Process which receives the training instruction from the cloud, the Example Store which stores the local data in a secure but easily accessible manner ( accessible to the model training and evaluation in FL runtime), and the FL runtime which is essentially where the configuration from the APP, the data from the Example Store and the model from the FL server work together.
Example Store:
Applications using FL are instructed by the server to store and make the data available to the FL. They then build the Example Store using APIs provided by the cloud server which promote security and accessibility and limit the storage footprint by renewing data and discarding old ones.
FL runtime and APP Process: The server only has an indirect control over the FL runtime. Namely the server first communicates with the app to alter the configuration in APP Process and then lets APP Process monitor the FL runtime. There are several important control flows that are configured by the server and operated by the APP Process.
- Programmatic Configuration: Used to schedule a routine FL runtime job using Android’s JobScheduler. User experience and device condition is paramount to the design. So JobScheduler only invoke the job when the phone is idle, charging, and connected to an unmetered network such as Wi-Fi. And it can abort the process if condition fails.
- Job Invocation: As long as the task is invoked, the FL runtime will contacts the server and wait for tasks and instructions to arrive. Elsewise it may be told to check in later at a suggested time.
- Task Execution: Two execution pattern is introduced, model training and model evaluation, with the former outputs the updated model parameters and the latter outputs the metrics indicating the performance on local data.
- Multi-Tenancy: The architecture supports multiply FL populations in the same app on the device. The coordination between different training activities has be tackled.
Server-side Design
Server uses the concept of Actor models to build the architecture.
Actor model based architecture has the ability to create and place fine-grained ephemeral instances of actors. By enabling scaling the number of actor models in a granularity as small as the duration of one FL task, this architecture grant the server the ability to regulate the resource and balance the load dynamically and efficiently in runtime.
Actor Model
Each actor handles a stream of messages/events strictly sequentially. In response to a message, an actor can make local decisions, send messages to other actors, or create more actors dynamically. Depending on the function and scalability requirements, actor instances can be co-located on the same process/machine or distributed across data centers in multiple geographic regions, using either explicit or automatic configuration mechanisms.
Below graph shows the architecture of the server model.
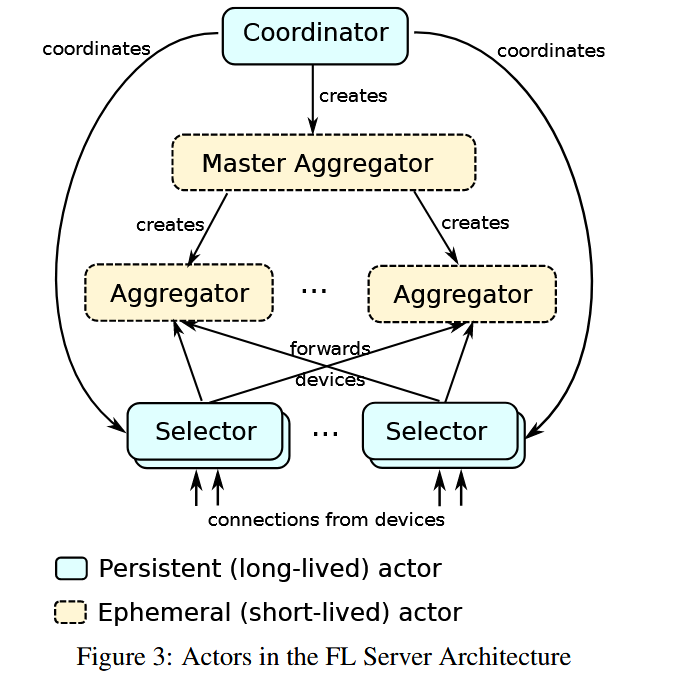
- Coordinator: A collector is one-to-one correspondent to an FL popularity. Then to perform an FL task, it generates Selectors that are used to communicate with the devices. To receive the updates and perform global model aggregation, the Coordinator also generates one Master Aggregator (for one task) which can then generate smaller Aggregator to help the Aggregation and cope with varied problem scales.
- Selectors: Selectors are responsible for accepting and forwarding the device connections. Notice that the Selectors can be distributed in the device-side. Each Selector can monitor a number of devices.
- Aggregators: Features in the ability to scale with the devices and update size.
There are other features in the cloud-based model
In memory storage and ephemeral actors
The memory of the actors are ephemeral and are kept in memory, which strength security, enhance mobility and reduce latency compared to distributed storage structure and reduce.
Pipelining
The Selector’s communication with the devices can be pipelined. When the aggregation is performed in current round, the Selection phase for the next round conducted by the Selectors can be executed in parallel. In other words, the Selector works continuously, enabling the aggregators to receive connected device data continuously and then the system works continuously and in parallel not sequential.
Troubleshooting measures
Actors model can be resilient to failures in several actors in a round. If a Selector or an Aggregator is down, only device connected to it will be lost, which scarcely matters. If the Mast Aggregator fails, the current round will fail but will be restored by the Coordinator. If the Coordinator dies, the Selector will detect it and respawn it, because the Coordinators are registered in a shared locking service.
Analytics
This section fucus on how engineers monitor the parameters of the system and have access to or control part of the system.
The rest of the paper also talks about practical implementation of the Secure Aggregation Protocol in the system, and the Tools and Workflow that engineers take control of the training. Details are omitted here.
TBD


